You have already completed the Test before. Hence you can not start it again.
Test is loading...
You must sign in or sign up to start the Test.
You have to finish following quiz, to start this Test:
Your results are here!! for" Nutanix Certified Associate 6.5 & 6.10 (NCA) Practice Test 1 "
0 of 60 questions answered correctly
Your time:
Time has elapsed
Your Final Score is : 0
You have attempted : 0
Number of Correct Questions : 0 and scored 0
Number of Incorrect Questions : 0 and Negative marks 0
Average score
Your score
Nutanix Certified Associate 6.5 & 6.10 (NCA)
You have attempted: 0
Number of Correct Questions: 0 and scored 0
Number of Incorrect Questions: 0 and Negative marks 0
You can review your answers by clicking on “View Answers” option. Important Note : Open Reference Documentation Links in New Tab (Right Click and Open in New Tab).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
Answered
Review
Question 1 of 60
1. Question
An administrator has defined a security policy that needs to be applied to dozens of VMs. What is the most efficient way the admin can perform this?
Correct
Categories allow bulk policy enforcement with minimal effort.
Incorrect
Categories allow bulk policy enforcement with minimal effort.
Unattempted
Categories allow bulk policy enforcement with minimal effort.
Question 2 of 60
2. Question
An Administrator wants to copy some virtual machine disk files to ADSF (Acropolis Distributed Storage Fabric) from an external VMware ESXi Host. Which two actions should the administrator take to complete this task? (Choose two.)
Correct
We should mount the container as NFS on the external host and configure a whitelist on the container to copy virtual machine disk files to ADSF.
Incorrect
We should mount the container as NFS on the external host and configure a whitelist on the container to copy virtual machine disk files to ADSF.
Unattempted
We should mount the container as NFS on the external host and configure a whitelist on the container to copy virtual machine disk files to ADSF.
Question 3 of 60
3. Question
An administrator receives an alert indicating that a node has failed within a Nutanix AHV-based 10-node cluster. Before the failure, CPU and memory utilization was around 50%. What automatic actions will the cluster take in response to the node failure?
Correct
When a node fails in a Nutanix AHV cluster: Nutanix HA detects the failure and identifies affected VMs. HA-enabled VMs are automatically restarted on healthy nodes. The Distributed Storage Fabric (DSF) ensures data availability, even with a node failure. No cluster-wide impact occurs since Nutanixs architecture is designed for resilience.
Incorrect
When a node fails in a Nutanix AHV cluster: Nutanix HA detects the failure and identifies affected VMs. HA-enabled VMs are automatically restarted on healthy nodes. The Distributed Storage Fabric (DSF) ensures data availability, even with a node failure. No cluster-wide impact occurs since Nutanixs architecture is designed for resilience.
Unattempted
When a node fails in a Nutanix AHV cluster: Nutanix HA detects the failure and identifies affected VMs. HA-enabled VMs are automatically restarted on healthy nodes. The Distributed Storage Fabric (DSF) ensures data availability, even with a node failure. No cluster-wide impact occurs since Nutanixs architecture is designed for resilience.
Question 4 of 60
4. Question
Nutanix Support has asked an administrator to provide an NCC output, but there is no access to the command line. What should the administrator do to provide the requested NCC output?
Correct
When CLI access is unavailable, an administrator can configure email alerts and run Health Checks from the Health Dashboard to generate and send NCC reports.
Incorrect
When CLI access is unavailable, an administrator can configure email alerts and run Health Checks from the Health Dashboard to generate and send NCC reports.
Unattempted
When CLI access is unavailable, an administrator can configure email alerts and run Health Checks from the Health Dashboard to generate and send NCC reports.
Question 5 of 60
5. Question
When multiple Alert policies are applied to an entity, which will take precedence?
Correct
When multiple alert policies apply to an entity in Nutanix, the system uses a precedence order to determine which policy is enforced. The policy with the highest precedence is evaluated, and all others are ignored, even if the highest precedence policy is disabled.1 The precedence order, from highest to lowest, is as follows: Policy applied to a specific entity Policy applied to an entity type in a category Policy applied to an entity type in a cluster Policy applied to all entities of an entity type For example, if you have created a policy (global-host-policy-1) that triggers a critical alert if the memory usage of any host exceeds 95%. However, you are now creating a policy (host1-policy) that triggers a critical alert if the memory usage (same metric) of host1 (a specific host) exceeds 90%, host1-policy is now an overlapping policy for global-host-policy-1. So, the Policy more specific for entity which host1-policy will been applied (highest precedence order).
Incorrect
When multiple alert policies apply to an entity in Nutanix, the system uses a precedence order to determine which policy is enforced. The policy with the highest precedence is evaluated, and all others are ignored, even if the highest precedence policy is disabled.1 The precedence order, from highest to lowest, is as follows: Policy applied to a specific entity Policy applied to an entity type in a category Policy applied to an entity type in a cluster Policy applied to all entities of an entity type For example, if you have created a policy (global-host-policy-1) that triggers a critical alert if the memory usage of any host exceeds 95%. However, you are now creating a policy (host1-policy) that triggers a critical alert if the memory usage (same metric) of host1 (a specific host) exceeds 90%, host1-policy is now an overlapping policy for global-host-policy-1. So, the Policy more specific for entity which host1-policy will been applied (highest precedence order).
Unattempted
When multiple alert policies apply to an entity in Nutanix, the system uses a precedence order to determine which policy is enforced. The policy with the highest precedence is evaluated, and all others are ignored, even if the highest precedence policy is disabled.1 The precedence order, from highest to lowest, is as follows: Policy applied to a specific entity Policy applied to an entity type in a category Policy applied to an entity type in a cluster Policy applied to all entities of an entity type For example, if you have created a policy (global-host-policy-1) that triggers a critical alert if the memory usage of any host exceeds 95%. However, you are now creating a policy (host1-policy) that triggers a critical alert if the memory usage (same metric) of host1 (a specific host) exceeds 90%, host1-policy is now an overlapping policy for global-host-policy-1. So, the Policy more specific for entity which host1-policy will been applied (highest precedence order).
Question 6 of 60
6. Question
An administrator is performing AHV upgrades on an 8-node Nutanix cluster configured with Redundancy Factor 3. How many nodes would be placed into maintenance mode simultaneously?
Correct
With a Redundancy Factor of 3 (RF-3), the cluster can tolerate two simultaneous failures. During an AHV upgrade, one node at a time is placed into maintenance mode. Since the cluster has 8 nodes and RF-3, it can handle two nodes being down, but the upgrade process prioritizes minimizing disruption and maintaining the highest possible availability during the upgrade. Therefore, only one node would be placed into maintenance mode at a time.
Incorrect
With a Redundancy Factor of 3 (RF-3), the cluster can tolerate two simultaneous failures. During an AHV upgrade, one node at a time is placed into maintenance mode. Since the cluster has 8 nodes and RF-3, it can handle two nodes being down, but the upgrade process prioritizes minimizing disruption and maintaining the highest possible availability during the upgrade. Therefore, only one node would be placed into maintenance mode at a time.
Unattempted
With a Redundancy Factor of 3 (RF-3), the cluster can tolerate two simultaneous failures. During an AHV upgrade, one node at a time is placed into maintenance mode. Since the cluster has 8 nodes and RF-3, it can handle two nodes being down, but the upgrade process prioritizes minimizing disruption and maintaining the highest possible availability during the upgrade. Therefore, only one node would be placed into maintenance mode at a time.
Question 7 of 60
7. Question
An administrator needs to upgrade AOS in a vSphere-based Nutanix five-node cluster with no automatic live migration. VMs have neither affinity nor anti-affinity rules configured. What will happen to VMs during the AOS upgrade?
Correct
In a Nutanix vSphere cluster with no automatic live migration (e.g., no vMotion/DRS), VMs will remain running on their original host during an AOS upgrade. The Controller VM (CVM) on that host will be restarted and upgraded individually. During this brief period, the cluster services (e.g., metadata, I/O redirection) normally handled by the CVM on that host will be managed by other CVMs in the cluster. This design ensures high availability and non-disruptive upgrades.
Incorrect
In a Nutanix vSphere cluster with no automatic live migration (e.g., no vMotion/DRS), VMs will remain running on their original host during an AOS upgrade. The Controller VM (CVM) on that host will be restarted and upgraded individually. During this brief period, the cluster services (e.g., metadata, I/O redirection) normally handled by the CVM on that host will be managed by other CVMs in the cluster. This design ensures high availability and non-disruptive upgrades.
Unattempted
In a Nutanix vSphere cluster with no automatic live migration (e.g., no vMotion/DRS), VMs will remain running on their original host during an AOS upgrade. The Controller VM (CVM) on that host will be restarted and upgraded individually. During this brief period, the cluster services (e.g., metadata, I/O redirection) normally handled by the CVM on that host will be managed by other CVMs in the cluster. This design ensures high availability and non-disruptive upgrades.
Question 8 of 60
8. Question
In the Health page in Prism Element, what should be selected first to run a full health check?
Correct
Checks
Incorrect, this is not the starting point for running health checks
Scheduled
Incorrect, scheduling is optional and does not start a health check
Correct answer
Actions
Correct, Actions is the starting point to run health check
Failed
Incorrect, Failed displays issues but does not run new checks
Details:
From the Prism web console Health page, select Actions > Run Checks. Select All checks and click Run.
Incorrect
Checks
Incorrect, this is not the starting point for running health checks
Scheduled
Incorrect, scheduling is optional and does not start a health check
Correct answer
Actions
Correct, Actions is the starting point to run health check
Failed
Incorrect, Failed displays issues but does not run new checks
Details:
From the Prism web console Health page, select Actions > Run Checks. Select All checks and click Run.
Unattempted
Checks
Incorrect, this is not the starting point for running health checks
Scheduled
Incorrect, scheduling is optional and does not start a health check
Correct answer
Actions
Correct, Actions is the starting point to run health check
Failed
Incorrect, Failed displays issues but does not run new checks
Details:
From the Prism web console Health page, select Actions > Run Checks. Select All checks and click Run.
Question 9 of 60
9. Question
When configuring dual encryption, which key management method is supported?
Correct
Dual encryption, using both self-encrypting drives (SEDs) and software encryption, requires an external key manager (EKM) such as Vormetric, SafeNet, IBM SKLM, Winmagic, or Fornetix. Nutanix‘s native key management server (KMS or LKM) is not supported with dual encryption.
Incorrect
Dual encryption, using both self-encrypting drives (SEDs) and software encryption, requires an external key manager (EKM) such as Vormetric, SafeNet, IBM SKLM, Winmagic, or Fornetix. Nutanix‘s native key management server (KMS or LKM) is not supported with dual encryption.
Unattempted
Dual encryption, using both self-encrypting drives (SEDs) and software encryption, requires an external key manager (EKM) such as Vormetric, SafeNet, IBM SKLM, Winmagic, or Fornetix. Nutanix‘s native key management server (KMS or LKM) is not supported with dual encryption.
Question 10 of 60
10. Question
Shared storage for Windows Server Failover Clustering is a use case for which Nutanix Unified Storage solution?
Correct
Nutanix Volumes is the correct solution for providing shared storage to WSFC.
Incorrect
Nutanix Volumes is the correct solution for providing shared storage to WSFC.
Unattempted
Nutanix Volumes is the correct solution for providing shared storage to WSFC.
Question 11 of 60
11. Question
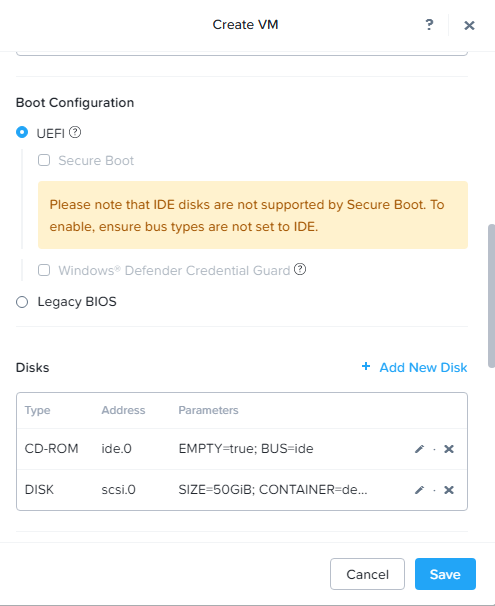
An administrator wants to enable Windows Defender Credential Guard. What must be enabled when creating the VM?
Correct
To enable Windows Defender Credential Guard when creating a VM in AHV, ensure that UEFI and Secure Boot are enabled in the VM‘s settings. Enabling Credential Guard requires these features due to its reliance on virtualization-based security
Incorrect
To enable Windows Defender Credential Guard when creating a VM in AHV, ensure that UEFI and Secure Boot are enabled in the VM‘s settings. Enabling Credential Guard requires these features due to its reliance on virtualization-based security
Unattempted
To enable Windows Defender Credential Guard when creating a VM in AHV, ensure that UEFI and Secure Boot are enabled in the VM‘s settings. Enabling Credential Guard requires these features due to its reliance on virtualization-based security
Question 12 of 60
12. Question
An administrator is creating a Linux VM and must decide which is the correct timezone to choose. Which timezone should the administrator select for this VM?
Correct
The correct timezone for a Linux virtual machine (VM) depends on several factors, including whether the VM is a Nutanix Mine VM, and whether the administrator wants to use the default Coordinated Universal Time (UTC) or a different timezone.
Incorrect
The correct timezone for a Linux virtual machine (VM) depends on several factors, including whether the VM is a Nutanix Mine VM, and whether the administrator wants to use the default Coordinated Universal Time (UTC) or a different timezone.
Unattempted
The correct timezone for a Linux virtual machine (VM) depends on several factors, including whether the VM is a Nutanix Mine VM, and whether the administrator wants to use the default Coordinated Universal Time (UTC) or a different timezone.
Question 13 of 60
13. Question
An administrator of an AHV cluster needs to deploy a solution that provides self-service network provisioning and overlapping IP addresses for true multi-tenant networking with VPCs (Virtual Private Clouds). Which product satisfies this requirement?
Correct
Flow Virtual Networking supports self-service network provisioning and overlapping IPs for multi-tenancy.
Incorrect
Flow Virtual Networking supports self-service network provisioning and overlapping IPs for multi-tenancy.
Unattempted
Flow Virtual Networking supports self-service network provisioning and overlapping IPs for multi-tenancy.
Question 14 of 60
14. Question
What type of NTP (Network Time Protocol) sources are recommended for Nutanix clusters?
Correct
Nutanix recommanded the internal NTP sources for better stability and security.
Incorrect
Nutanix recommanded the internal NTP sources for better stability and security.
Unattempted
Nutanix recommanded the internal NTP sources for better stability and security.
Question 15 of 60
15. Question
An application owner reported that an AHV-based critical application VM is performing very slowly. After initial diagnostics, it has been observed that the CPU utilization is significantly higher than normal. What two actions should the administrator take on this VM without shutting it down? (Choose two.)
Correct
Administrator should increase the number of vCPUs in Prism Element and ensure CPU hot-add is supported by the Guest.
Incorrect
Administrator should increase the number of vCPUs in Prism Element and ensure CPU hot-add is supported by the Guest.
Unattempted
Administrator should increase the number of vCPUs in Prism Element and ensure CPU hot-add is supported by the Guest.
Question 16 of 60
16. Question
An administrator wants to create an application-consistent snapshot. Which NGT (Nutanix Guest Tools) feature needs to be enabled to satisfy this task?
Correct
VSS is the feature that needs to be enabled for application-consistent snapshots.
Incorrect
VSS is the feature that needs to be enabled for application-consistent snapshots.
Unattempted
VSS is the feature that needs to be enabled for application-consistent snapshots.
Question 17 of 60
17. Question
A new project is being rolled out to an AHV Cluster being monitored by Prism Central. The application team indicated that the application managed by the project is very memory intensive. The administrator wants to be notified about any memory constraints should they occur. How would an administrator most effectively achieve this task?
Correct
Creating a new alert policy for memory usage and setting it to critical after 80% will effectively notify the administrator about memory constraints.
Incorrect
Creating a new alert policy for memory usage and setting it to critical after 80% will effectively notify the administrator about memory constraints.
Unattempted
Creating a new alert policy for memory usage and setting it to critical after 80% will effectively notify the administrator about memory constraints.
Question 18 of 60
18. Question
Which technology allows applications and data to move freely between runtime environments?
Correct
AMF allows applications and data to move freely across environments.
Incorrect
AMF allows applications and data to move freely across environments.
Unattempted
AMF allows applications and data to move freely across environments.
Question 19 of 60
19. Question
Users are complaining that web applications hosted on a Nutanix cluster are running slow. After reviewing the performance metric, it is determined that the CPU Ready time is high in the cluster. What entity is impacted by CPU ready time?
Correct
CPU Ready time impacts the performance of VMs in the cluster.
Incorrect
CPU Ready time impacts the performance of VMs in the cluster.
Unattempted
CPU Ready time impacts the performance of VMs in the cluster.
Question 20 of 60
20. Question
Which Nutanix storage efficiency feature is most suitable for nearly every workload?
Correct
Compression is widely applicable as it compress data inline or post and improves storage efficiency, and is suitable for nearly every workload?
Incorrect
Compression is widely applicable as it compress data inline or post and improves storage efficiency, and is suitable for nearly every workload?
Unattempted
Compression is widely applicable as it compress data inline or post and improves storage efficiency, and is suitable for nearly every workload?
Question 21 of 60
21. Question
At what time does LCM auto-inventory run by default?
Correct
By default, LCM auto-inventory runs at 3:00 AM to check for updates.
Incorrect
By default, LCM auto-inventory runs at 3:00 AM to check for updates.
Unattempted
By default, LCM auto-inventory runs at 3:00 AM to check for updates.
Question 22 of 60
22. Question
An Admin is considering a data protection strategy between two datacenters. There is a 10ms round trip (10ms RTT) latency between the two dusters Which data protection solution can the Admin implement that minimizes data loss in the event of a disaster?
Correct
With a 10ms RTT between sites, NearSync replication is the optimal and supported choice. It provides minute-level RPO, ensuring minimal data loss in the event of a disaster, and works over longer distances and higher latency than synchronous solutions like Metro Availability. Therefore, Option B is the correct answer.
Incorrect
With a 10ms RTT between sites, NearSync replication is the optimal and supported choice. It provides minute-level RPO, ensuring minimal data loss in the event of a disaster, and works over longer distances and higher latency than synchronous solutions like Metro Availability. Therefore, Option B is the correct answer.
Unattempted
With a 10ms RTT between sites, NearSync replication is the optimal and supported choice. It provides minute-level RPO, ensuring minimal data loss in the event of a disaster, and works over longer distances and higher latency than synchronous solutions like Metro Availability. Therefore, Option B is the correct answer.
Question 23 of 60
23. Question
What is the default admininstrator session log out time?
Correct
By default, Nutanix automatically logs out admin sessions after 15 minutes of inactivity to enhance security.
Incorrect
By default, Nutanix automatically logs out admin sessions after 15 minutes of inactivity to enhance security.
Unattempted
By default, Nutanix automatically logs out admin sessions after 15 minutes of inactivity to enhance security.
Question 24 of 60
24. Question
Which of the following option is supported by Nutanix for Data-at-Rest encryption?
Correct
Nutanix supports Software-only Encryption for Data-at-Rest, which can be enabled cluster-wide and applied at the container level. This provides a secure way to protect stored data without requiring specialized self-encrypting drives, though SEDs are also supported. The correct and supported method is referred to as Software-based DARE making Option A the correct choice.
Incorrect
Nutanix supports Software-only Encryption for Data-at-Rest, which can be enabled cluster-wide and applied at the container level. This provides a secure way to protect stored data without requiring specialized self-encrypting drives, though SEDs are also supported. The correct and supported method is referred to as Software-based DARE making Option A the correct choice.
Unattempted
Nutanix supports Software-only Encryption for Data-at-Rest, which can be enabled cluster-wide and applied at the container level. This provides a secure way to protect stored data without requiring specialized self-encrypting drives, though SEDs are also supported. The correct and supported method is referred to as Software-based DARE making Option A the correct choice.
Question 25 of 60
25. Question
What is true when adding a storage-only node to the Nutanix HCI cluster?
Correct
A storage-only node provides additional disk capacity to the cluster but does not host VMs. It runs AHV and can be added to clusters that use a different primary hypervisor, such as ESXi or Hyper-V. This design allows flexibility in expanding storage independently of compute resources. Optional services like Nutanix Files or Objects are not required for this functionality.
Incorrect
A storage-only node provides additional disk capacity to the cluster but does not host VMs. It runs AHV and can be added to clusters that use a different primary hypervisor, such as ESXi or Hyper-V. This design allows flexibility in expanding storage independently of compute resources. Optional services like Nutanix Files or Objects are not required for this functionality.
Unattempted
A storage-only node provides additional disk capacity to the cluster but does not host VMs. It runs AHV and can be added to clusters that use a different primary hypervisor, such as ESXi or Hyper-V. This design allows flexibility in expanding storage independently of compute resources. Optional services like Nutanix Files or Objects are not required for this functionality.
Question 26 of 60
26. Question
An administrator is upgrading a current three-node Nutanix cluster with new HCI (Hyper-Converged Infrastructure) nodes. Currently, the environment is based on a single two-unit chassis hosted in one cabinet. By simply changing the system form factor, what new level of resiliency may this customer achieve?
Correct
By changing the system form factor, the customer may achieve block awareness.
Incorrect
By changing the system form factor, the customer may achieve block awareness.
Unattempted
By changing the system form factor, the customer may achieve block awareness.
Question 27 of 60
27. Question
Which policy specifies that a selected VM will only run on a specific group of nodes in Nutanix Cluster?
Correct
An affinity policy specifies that a selected VM will only run on a specific group of nodes.
Incorrect
An affinity policy specifies that a selected VM will only run on a specific group of nodes.
Unattempted
An affinity policy specifies that a selected VM will only run on a specific group of nodes.
Question 28 of 60
28. Question
Which feature enables Image Placement Policies to be mapped to target Nutanix clusters?
Correct
Categories allow administrators to define and apply image placement across clusters.
Incorrect
Categories allow administrators to define and apply image placement across clusters.
Unattempted
Categories allow administrators to define and apply image placement across clusters.
Question 29 of 60
29. Question
How can an administrator access a specific Nutanix cluster from Prism Central?
Correct
Administrators can access specific clusters from Prism Central by selecting the cluster from the quick access widget.
Incorrect
Administrators can access specific clusters from Prism Central by selecting the cluster from the quick access widget.
Unattempted
Administrators can access specific clusters from Prism Central by selecting the cluster from the quick access widget.
Question 30 of 60
30. Question
What is the purpose of Discoveries within the Nutanix Support Portal?
Correct
Discoveries help detect clusters impacted by known Nutanix issues, assisting in proactive remediation.
Incorrect
Discoveries help detect clusters impacted by known Nutanix issues, assisting in proactive remediation.
Unattempted
Discoveries help detect clusters impacted by known Nutanix issues, assisting in proactive remediation.
Question 31 of 60
31. Question
After starting an LCM (Life Cycle Management) update from Prism Element, on which dashboard can the progress be monitored?
Correct
The progress of the LCM update can be monitored on the Tasks dashboard.
Incorrect
The progress of the LCM update can be monitored on the Tasks dashboard.
Unattempted
The progress of the LCM update can be monitored on the Tasks dashboard.
Question 32 of 60
32. Question
An administrator wants to collect log files requested by Nutanix Support. From which Prism Element dashboard can this be accomplished?
Correct
The Health dashboard provides an option to collect logs. In the Health dashboard, from the Actions drop-down menu, select Collect Logs.
Incorrect
The Health dashboard provides an option to collect logs. In the Health dashboard, from the Actions drop-down menu, select Collect Logs.
Unattempted
The Health dashboard provides an option to collect logs. In the Health dashboard, from the Actions drop-down menu, select Collect Logs.
Question 33 of 60
33. Question
Within Prism Central, which Compute and Storage section allows an administrator to upload a Windows ISO file?
Correct
The Images section allows uploading ISO and disk files.
Incorrect
The Images section allows uploading ISO and disk files.
Unattempted
The Images section allows uploading ISO and disk files.
Question 34 of 60
34. Question
What is the maximum jumbo frame MTU (Maximum Transmission Unit) supported by host network interfaces and guest VMs?
Correct
The maximum jumbo frame MTU supported by host network interfaces and Guest VMs is 9000 bytes, but for CVM, it‘s only 1500.
Incorrect
The maximum jumbo frame MTU supported by host network interfaces and Guest VMs is 9000 bytes, but for CVM, it‘s only 1500.
Unattempted
The maximum jumbo frame MTU supported by host network interfaces and Guest VMs is 9000 bytes, but for CVM, it‘s only 1500.
Question 35 of 60
35. Question
What is the maximum MTU supported by Nutanix CVM (Controller Virtual Machine)?
Correct
The maximum transmission units (MTU) supported by Nutanix CVM is 1500 bytes. Nutanix doesn‘t support configuring the MTU on a CVM‘s network interfaces to higher values.
Incorrect
The maximum transmission units (MTU) supported by Nutanix CVM is 1500 bytes. Nutanix doesn‘t support configuring the MTU on a CVM‘s network interfaces to higher values.
Unattempted
The maximum transmission units (MTU) supported by Nutanix CVM is 1500 bytes. Nutanix doesn‘t support configuring the MTU on a CVM‘s network interfaces to higher values.
Question 36 of 60
36. Question
What is the minimum number of blocks required to utilize block awareness?
Correct
The minimum number of blocks required to utilize block awareness is 3.
Incorrect
The minimum number of blocks required to utilize block awareness is 3.
Unattempted
The minimum number of blocks required to utilize block awareness is 3.
Question 37 of 60
37. Question
What is the minimum number of nodes needed to configure a Replication Factor of 2 (RF2)?
Correct
The minimum number of nodes needed to configure a Replication Factor of 2 (RF2) is 3.
Incorrect
The minimum number of nodes needed to configure a Replication Factor of 2 (RF2) is 3.
Unattempted
The minimum number of nodes needed to configure a Replication Factor of 2 (RF2) is 3.
Question 38 of 60
38. Question
An administrator has configured Prism Central to email daily digests of alerts on a Nutanix cluster. After a week, the administrator notices that digests are not being received. What is the most likely cause of the issue?
Correct
The recipient address is not registered with Nutanix
Incorrect, registration with Nutanix is not required for receiving email digests.
Nutanix support is not enabled as a recipient
Incorrect, Nutanix support does not need to be a recipient for email digests.
The tunnel connection has not been enabled
Incorrect, the tunnel connection is not related to email digests.
Correct answer
The SMTP server is not configured properly
Correct, improper SMTP server configuration is the most likely cause.
Details:
The most likely cause of the issue is that the SMTP server is not configured properly.
Incorrect
The recipient address is not registered with Nutanix
Incorrect, registration with Nutanix is not required for receiving email digests.
Nutanix support is not enabled as a recipient
Incorrect, Nutanix support does not need to be a recipient for email digests.
The tunnel connection has not been enabled
Incorrect, the tunnel connection is not related to email digests.
Correct answer
The SMTP server is not configured properly
Correct, improper SMTP server configuration is the most likely cause.
Details:
The most likely cause of the issue is that the SMTP server is not configured properly.
Unattempted
The recipient address is not registered with Nutanix
Incorrect, registration with Nutanix is not required for receiving email digests.
Nutanix support is not enabled as a recipient
Incorrect, Nutanix support does not need to be a recipient for email digests.
The tunnel connection has not been enabled
Incorrect, the tunnel connection is not related to email digests.
Correct answer
The SMTP server is not configured properly
Correct, improper SMTP server configuration is the most likely cause.
Details:
The most likely cause of the issue is that the SMTP server is not configured properly.
Question 39 of 60
39. Question
An administrator has been tasked with delivering a report on all Nutanix Field Advisors (FAs) affecting each of the clusters. What is the most efficient way to collect this data?
Correct
The most efficient way to collect data on all Nutanix Field Advisors (FAs) affecting each of the clusters is to review the discoveries information on the support portal.
Incorrect
The most efficient way to collect data on all Nutanix Field Advisors (FAs) affecting each of the clusters is to review the discoveries information on the support portal.
Unattempted
The most efficient way to collect data on all Nutanix Field Advisors (FAs) affecting each of the clusters is to review the discoveries information on the support portal.
Question 40 of 60
40. Question
An Administrator has created a Volume Group for a specific VM on an AHV (Acropolis Hypervisor) Cluster. What is the next step required to use the vDisk in the VM?
Correct
The next step required to use vDisk in the VM is to attach the Volume Group to the VM.
Incorrect
The next step required to use vDisk in the VM is to attach the Volume Group to the VM.
Unattempted
The next step required to use vDisk in the VM is to attach the Volume Group to the VM.
Question 41 of 60
41. Question
Which account is recommended for performing tasks and operations on the Nutanix CVM via SSH (Secure Shell)?
Correct
The ‘nutanix‘ account is recommended for performing tasks and operations on the CVM via SSH.
Incorrect
The ‘nutanix‘ account is recommended for performing tasks and operations on the CVM via SSH.
Unattempted
The ‘nutanix‘ account is recommended for performing tasks and operations on the CVM via SSH.
Question 42 of 60
42. Question
Which URL can be used to open Nutanix support cases?
Correct
The URL portal.nutanix.com can be used to open Nutanix support cases.
Incorrect
The URL portal.nutanix.com can be used to open Nutanix support cases.
Unattempted
The URL portal.nutanix.com can be used to open Nutanix support cases.
Question 43 of 60
43. Question
How long does a Nutanix clusters Recycle Bin retain deleted vDisk and configuration data files?
Correct
The Nutanix clusters Recycle Bin retains deleted vDisk and configuration data files for 24 hours.
Incorrect
The Nutanix clusters Recycle Bin retains deleted vDisk and configuration data files for 24 hours.
Unattempted
The Nutanix clusters Recycle Bin retains deleted vDisk and configuration data files for 24 hours.
Question 44 of 60
44. Question
What is the purpose of the OpLog?
Correct
The OpLog is a persistent write buffer that accelerates write performance before data is committed to the storage pool.
Incorrect
The OpLog is a persistent write buffer that accelerates write performance before data is committed to the storage pool.
Unattempted
The OpLog is a persistent write buffer that accelerates write performance before data is committed to the storage pool.
Question 45 of 60
45. Question
An administrator receives several alerts indicating a Nutanix cluster is running out of memory. As a preemptive measure, the administrator wishes to try to reduce the consumed resources, if possible. Which two predefined views for Reporting best display potentially reclaimable resources? (Choose two.)
Correct
The predefined views for Reporting that best display potentially reclaimable resources are the List of inactive VMs and the List of overprovisioned VMs.
Incorrect
The predefined views for Reporting that best display potentially reclaimable resources are the List of inactive VMs and the List of overprovisioned VMs.
Unattempted
The predefined views for Reporting that best display potentially reclaimable resources are the List of inactive VMs and the List of overprovisioned VMs.
Question 46 of 60
46. Question
Upon logging into Prism Element, an administrator sees a red heart icon. Which dashboard in Prism will best help the administrator to isolate the cause of the red heart?
Correct
Health
Correct – The Health dashboard provides insights into cluster health and failures.
Tasks
Incorrect – The Tasks dashboard tracks background operations, not cluster health.
Analysis
Incorrect – The Analysis dashboard is used for performance monitoring, not failure detection.
Hardware
Incorrect – The Hardware dashboard displays hardware status but does not isolate the cause of cluster health issues.
Details:
The Health dashboard in Prism Element is the best place to diagnose and isolate cluster issues indicated by the red heart.
Incorrect
Health
Correct – The Health dashboard provides insights into cluster health and failures.
Tasks
Incorrect – The Tasks dashboard tracks background operations, not cluster health.
Analysis
Incorrect – The Analysis dashboard is used for performance monitoring, not failure detection.
Hardware
Incorrect – The Hardware dashboard displays hardware status but does not isolate the cause of cluster health issues.
Details:
The Health dashboard in Prism Element is the best place to diagnose and isolate cluster issues indicated by the red heart.
Unattempted
Health
Correct – The Health dashboard provides insights into cluster health and failures.
Tasks
Incorrect – The Tasks dashboard tracks background operations, not cluster health.
Analysis
Incorrect – The Analysis dashboard is used for performance monitoring, not failure detection.
Hardware
Incorrect – The Hardware dashboard displays hardware status but does not isolate the cause of cluster health issues.
Details:
The Health dashboard in Prism Element is the best place to diagnose and isolate cluster issues indicated by the red heart.
Question 47 of 60
47. Question
What is the purpose of the Recycle Bin?
Correct
The Recycle Bin feature ensures deleted VMs can be restored within 24 hours, preventing accidental data loss.
Incorrect
The Recycle Bin feature ensures deleted VMs can be restored within 24 hours, preventing accidental data loss.
Unattempted
The Recycle Bin feature ensures deleted VMs can be restored within 24 hours, preventing accidental data loss.
Question 48 of 60
48. Question
An administrator needs to remove several old VM snapshots. From which Prism Element dashboard should the administrator complete this task?
Correct
The Storage dashboard in Prism Element allows administrators to manage and delete VM snapshots.
Incorrect
The Storage dashboard in Prism Element allows administrators to manage and delete VM snapshots.
Unattempted
The Storage dashboard in Prism Element allows administrators to manage and delete VM snapshots.
Question 49 of 60
49. Question
After starting LCM updates, an administrator would like to see a detailed view of each update as it progresses. Which Prism Element dashboard should the administrator use to monitor the LCM updates?
Correct
The Tasks dashboard in Prism Element provides real-time visibility into LCM updates.
Incorrect
The Tasks dashboard in Prism Element provides real-time visibility into LCM updates.
Unattempted
The Tasks dashboard in Prism Element provides real-time visibility into LCM updates.
Question 50 of 60
50. Question
A single host in a four-node AHV-based Nutanix cluster experiences a complete network failure. If more than enough resources exist in the cluster to tolerate a node failure, what happens to the user VMs running on that host?
Correct
The user VMs running on the host with a complete network failure are restarted to the three remaining hosts.
Incorrect
The user VMs running on the host with a complete network failure are restarted to the three remaining hosts.
Unattempted
The user VMs running on the host with a complete network failure are restarted to the three remaining hosts.
Question 51 of 60
51. Question
A team member has built a CentOS VM image for use as a template. An administrator deploys a new VM using the CentOS image as the OS drive. No other drives are presented to the VM. Following the deployment, the administrator attempts to boot the VM, but is unsuccessful. What could be causing this issue?
Correct
The VM’s Boot Priority must reference disk first before CD-ROM
Incorrect, boot priority is not the issue if the disk is already referenced.
The VM’s Disk (scsi.0) setting must be set to make this disk bootable
Incorrect, the disk setting is not the issue.
No Volume Groups have been created for the VM
Incorrect, volume groups are not required for booting the VM.
Correct answer
The CentOS VM image was built with UEFI
Correct, VM configured with Legacy bios while the image is UEFI. UEFI is the issue if the VM is not booting.
Details:
The VM’s disk (scsi.0) setting is not required to make the disk bootable. The main issue is that the VM was originally configured with Legacy BIOS, but the team member redeployed it using UEFI.
Incorrect
The VM’s Boot Priority must reference disk first before CD-ROM
Incorrect, boot priority is not the issue if the disk is already referenced.
The VM’s Disk (scsi.0) setting must be set to make this disk bootable
Incorrect, the disk setting is not the issue.
No Volume Groups have been created for the VM
Incorrect, volume groups are not required for booting the VM.
Correct answer
The CentOS VM image was built with UEFI
Correct, VM configured with Legacy bios while the image is UEFI. UEFI is the issue if the VM is not booting.
Details:
The VM’s disk (scsi.0) setting is not required to make the disk bootable. The main issue is that the VM was originally configured with Legacy BIOS, but the team member redeployed it using UEFI.
Unattempted
The VM’s Boot Priority must reference disk first before CD-ROM
Incorrect, boot priority is not the issue if the disk is already referenced.
The VM’s Disk (scsi.0) setting must be set to make this disk bootable
Incorrect, the disk setting is not the issue.
No Volume Groups have been created for the VM
Incorrect, volume groups are not required for booting the VM.
Correct answer
The CentOS VM image was built with UEFI
Correct, VM configured with Legacy bios while the image is UEFI. UEFI is the issue if the VM is not booting.
Details:
The VM’s disk (scsi.0) setting is not required to make the disk bootable. The main issue is that the VM was originally configured with Legacy BIOS, but the team member redeployed it using UEFI.
Question 52 of 60
52. Question
An administrator needs to migrate a running VM‘s vDisks to another container without downtime. Which tool should the administrator use to satisfy this task?
Correct
To migrate a running VM‘s vDisks to another container without downtime, the administrator should use the acli vm.update_container command.
Incorrect
To migrate a running VM‘s vDisks to another container without downtime, the administrator should use the acli vm.update_container command.
Unattempted
To migrate a running VM‘s vDisks to another container without downtime, the administrator should use the acli vm.update_container command.
Question 53 of 60
53. Question
An administrator has spent time correcting specific issues that have been identified by NCC (Nutanix Cluster Check) Health Checks in Prism Element. How can just the checks that previously did not pass be executed again to confirm they are all resolved?
Correct
This option allows re-running only the failed or warning NCC checks to confirm resolutions efficiently.
Incorrect
This option allows re-running only the failed or warning NCC checks to confirm resolutions efficiently.
Unattempted
This option allows re-running only the failed or warning NCC checks to confirm resolutions efficiently.
Question 54 of 60
54. Question
What resource should be used to ensure a successful upgrade of the hypervisors and AOS (Acropolis Operating System) within a vSphere-based Nutanix cluster?
Correct
This resource ensures the hypervisor and AOS versions are fully supported.
Incorrect
This resource ensures the hypervisor and AOS versions are fully supported.
Unattempted
This resource ensures the hypervisor and AOS versions are fully supported.
Question 55 of 60
55. Question
An administrator is deploying a virtual firewall on each node in an AHV cluster and wants each VM to maintain affinity to its host. How can an administrator achieve this goal most efficiently?
Correct
This setting ensures the virtual firewall VMs stay on their assigned nodes.
Incorrect
This setting ensures the virtual firewall VMs stay on their assigned nodes.
Unattempted
This setting ensures the virtual firewall VMs stay on their assigned nodes.
Question 56 of 60
56. Question
An administrator needs to ensure that the three VMs of an application cluster are never placed onto the same hypervisor by creating a VM-VM Anti-Affinity Policy. What should the administrator use to complete this task?
Correct
To ensure that the three VMs of an application cluster are never placed onto the same hypervisor, the administrator should use VM-VM Anti-Affinity policy. Currently, this policy can only be configured through the aCLI. A Prism Central (PC) UI implementation is desired and tracked in Feature request FEAT-4595, but it is not yet available.
Incorrect
To ensure that the three VMs of an application cluster are never placed onto the same hypervisor, the administrator should use VM-VM Anti-Affinity policy. Currently, this policy can only be configured through the aCLI. A Prism Central (PC) UI implementation is desired and tracked in Feature request FEAT-4595, but it is not yet available.
Unattempted
To ensure that the three VMs of an application cluster are never placed onto the same hypervisor, the administrator should use VM-VM Anti-Affinity policy. Currently, this policy can only be configured through the aCLI. A Prism Central (PC) UI implementation is desired and tracked in Feature request FEAT-4595, but it is not yet available.
Question 57 of 60
57. Question
What is required to successfully live migrate a VM between two AHV clusters (Cross-Cluster Live Migration) CCLM?
Correct
There is two type of live migration across two AHV clusters 1. Cross-Cluster Live Migration CCLM, which depend on synchronous replication >> To successfully live migrate a VM between two AHV clusters, you should have guest VMs protected with synchronous replication schedule. 2. On-Demand Cross-Cluster Live Migration On-demand cross-cluster live migration (OD-CCLM) enables you to migrate guest VMs (and all of their associated metadata like VM categories) across AHV clusters registered to the same or different Prism Central instances spanning availability zones (AZs). To ensure zero downtime of the guest VMs, you can live migrate without the need to protect the guest VMs with synchronous replication schedules or set up Nutanix Disaster Recovery from the Prism Central web console.
Incorrect
There is two type of live migration across two AHV clusters 1. Cross-Cluster Live Migration CCLM, which depend on synchronous replication >> To successfully live migrate a VM between two AHV clusters, you should have guest VMs protected with synchronous replication schedule. 2. On-Demand Cross-Cluster Live Migration On-demand cross-cluster live migration (OD-CCLM) enables you to migrate guest VMs (and all of their associated metadata like VM categories) across AHV clusters registered to the same or different Prism Central instances spanning availability zones (AZs). To ensure zero downtime of the guest VMs, you can live migrate without the need to protect the guest VMs with synchronous replication schedules or set up Nutanix Disaster Recovery from the Prism Central web console.
Unattempted
There is two type of live migration across two AHV clusters 1. Cross-Cluster Live Migration CCLM, which depend on synchronous replication >> To successfully live migrate a VM between two AHV clusters, you should have guest VMs protected with synchronous replication schedule. 2. On-Demand Cross-Cluster Live Migration On-demand cross-cluster live migration (OD-CCLM) enables you to migrate guest VMs (and all of their associated metadata like VM categories) across AHV clusters registered to the same or different Prism Central instances spanning availability zones (AZs). To ensure zero downtime of the guest VMs, you can live migrate without the need to protect the guest VMs with synchronous replication schedules or set up Nutanix Disaster Recovery from the Prism Central web console.
Question 58 of 60
58. Question
A 10GbE link has failed on Node A within the following cluster environment: Four-node AHV-based Nutanix cluster, All nodes have only two 10GbE ports connected to the network, Active-backup is configured. What impact will user VMs experience from this issue?
Correct
There is no impact on user VMs since the switch bond is configured as Active-Backup. However, performance degradation may occur if the bond were Active-Active.
Incorrect
There is no impact on user VMs since the switch bond is configured as Active-Backup. However, performance degradation may occur if the bond were Active-Active.
Unattempted
There is no impact on user VMs since the switch bond is configured as Active-Backup. However, performance degradation may occur if the bond were Active-Active.
Question 59 of 60
59. Question
An administrator should use which Nutanix component to create in-guest clustering?
Correct
Volumes are used for creating in-guest clustering in Nutanix.
Incorrect
Volumes are used for creating in-guest clustering in Nutanix.
Unattempted
Volumes are used for creating in-guest clustering in Nutanix.
Question 60 of 60
60. Question
What data is stored as a file on storage devices owned by a Nutanix CVM?
Correct
vDisks represent virtualized storage and are stored as files on Nutanix storage.
Incorrect
vDisks represent virtualized storage and are stored as files on Nutanix storage.
Unattempted
vDisks represent virtualized storage and are stored as files on Nutanix storage.
X
Use Page numbers below to navigate to other practice tests